打敗李世乭的AlphaGo,被弟弟AlphaGo Zero打敗了,成績是0-100
去年,有個小孩讀遍人世所有的棋譜,辛勤打譜,苦思冥想,棋藝精進,4-1打敗世界冠軍李世石,從此人間無敵手。他的名字叫 AlphaGo(阿法狗)。
今年,他的弟弟只靠一副棋盤和黑白兩子,沒看過一個棋譜,也沒有一個人指點,從零開始,自娛自樂,自己參悟,100-0打敗哥哥 AlphaGo 。他的名字叫 AlphaGo Zero(阿法元) 。
DeepMind 這項偉大的突破,今天以 Mastering the game of Go without human knowledge 為題,發表于 Nature,引起轟動。知社特邀國內外幾位人工智能專家,給予深度解析和點評。
自學三天,100-0擊潰阿法狗

Nature今天上線的這篇重磅論文,詳細介紹了谷歌DeepMind團隊最新的研究成果。
人工智能的一項重要目標,是在沒有任何先驗知識的前提下,通過完全的自學,在極具挑戰的領域,達到超人的境地。
去年,阿法狗(AlphaGo)代表人工智能在圍棋領域首次戰勝了人類的世界冠軍,但其棋藝的精進,是建立在計算機通過海量的歷史棋譜學習參悟人類棋藝的基礎之上,進而自我訓練,實現超越。
可是今天,我們發現,人類其實把阿法狗教壞了!
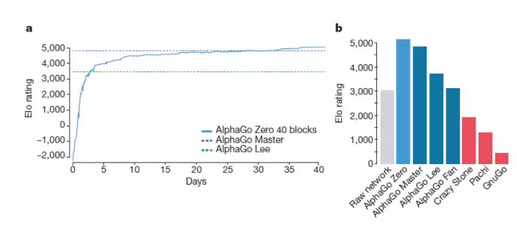
新一代的阿法元(AlphaGo Zero), 完全從零開始,不需要任何歷史棋譜的指引,更不需要參考人類任何的先驗知識,完全靠自己一個人強化學習(reinforcement learning)和參悟, 棋藝增長遠超阿法狗,百戰百勝,擊潰阿法狗100-0。
達到這樣一個水準,阿法元只需要在4個TPU上,花三天時間,自己左右互搏490萬棋局。而它的哥哥阿法狗,需要在48個TPU上,花幾個月的時間,學習三千萬棋局,才打敗人類。

David Silver博士,AlphaGo項目負責人
這篇論文的第一和通訊作者是DeepMind的David Silver博士, 阿法狗項目負責人。他介紹說阿法元遠比阿法狗強大,因為它不再被人類認知所局限,而能夠發現新知識,發展新策略:
This technique is more powerful than previous versions of AlphaGo because it is no longer constrained by the limits of human knowledge. Instead, it is able to learn tabula rasa from the strongest player in the world: AlphaGo itself. AlphaGo Zero also discovered new knowledge, developing unconventional strategies and creative new moves that echoed and surpassed the novel techniques it played in the games against Lee Sedol and Ke Jie.
DeepMind聯合創始人和CEO則說這一新技術能夠用于解決諸如蛋白質折疊和新材料開發這樣的重要問題:
AlphaGo Zero is now the strongest version of our program and shows how much progress we can make even with less computing power and zero use of human data. Ultimately we want to harness algorithmic breakthroughs like this to help solve all sorts of pressing real world problems like protein folding or designing new materials.
美國的兩位棋手在Nature對阿法元的棋局做了點評:
它的開局和收官和專業棋手的下法并無區別,人類幾千年的智慧結晶,看起來并非全錯。但是中盤看起來則非常詭異:
the AI’s open?ing choices and end-game methods have converged on ours — seeing it arrive at our sequences from first principles suggests that we haven’t been on entirely the wrong track. By contrast, some of its middle-game judgements are truly mysterious.
無師自通,關鍵技術是哪些?
為更深入了解阿法元的技術細節,知社采訪了美國杜克大學人工智能專家陳怡然教授。他向知社介紹說:
DeepMind最新推出的AlphaGo Zero降低了訓練復雜度,擺脫了對人類標注樣本(人類歷史棋局)的依賴,讓深度學習用于復雜決策更加方便可行。我個人覺得最有趣的是證明了人類經驗由于樣本空間大小的限制,往往都收斂于局部最優而不自知(或無法發現),而機器學習可以突破這個限制。之前大家隱隱約約覺得應該如此,而現在是鐵的量化事實擺在面前!
他進一步解釋道:
這篇論文數據顯示學習人類選手的下法雖然能在訓練之初獲得較好的棋力,但在訓練后期所能達到的棋力卻只能與原版的AlphaGo相近,而不學習人類下法的AlphaGo Zero最終卻能表現得更好。這或許說明人類的下棋數據將算法導向了局部最優(local optima),而實際更優或者最優的下法與人類的下法存在一些本質的不同,人類實際’誤導’了AlphaGo。有趣的是如果AlphaGo Zero放棄學習人類而使用完全隨機的初始下法,訓練過程也一直朝著收斂的方向進行,而沒有產生難以收斂的現象。
阿法元是如何實現無師自通的呢? 杜克大學博士研究生吳春鵬向知社介紹了技術細節:
之前戰勝李世石的AlphaGo基本采用了傳統增強學習技術再加上深度神經網絡DNN完成搭建,而AlphaGo Zero吸取了最新成果做出了重大改進。
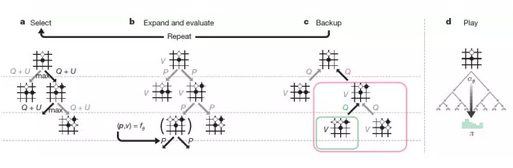
首先,在AlphaGo Zero出現之前,基于深度學習的增強學習方法按照使用的網絡模型數量可以分為兩類: 一類使用一個DNN"端到端"地完成全部決策過程(比如DQN),這類方法比較輕便,對于離散動作決策更適用; 另一類使用多個DNN分別學習policy和value等(比如之前戰勝李世石的AlphaGoGo),這類方法比較復雜,對于各種決策更通用。此次的AlphaGo Zero綜合了二者長處,采用類似DQN的一個DNN網絡實現決策過程,并利用這個DNN得到兩種輸出policy和value,然后利用一個蒙特卡羅搜索樹完成當前步驟選擇。
其次,AlphaGo Zero沒有再利用人類歷史棋局,訓練過程從完全隨機開始。隨著近幾年深度學習研究和應用的深入,DNN的一個缺點日益明顯: 訓練過程需要消耗大量人類標注樣本,而這對于小樣本應用領域(比如醫療圖像處理)是不可能辦到的。所以Few-shot learning和Transfer learning等減少樣本和人類標注的方法得到普遍重視。AlphaGo Zero是在雙方博弈訓練過程中嘗試解決對人類標注樣本的依賴,這是以往沒有的。
第三,AlphaGo Zero在DNN網絡結構上吸收了最新進展,采用了ResNet網絡中的Residual結構作為基礎模塊。近幾年流行的ResNet加大了網絡深度,而GoogLeNet加大了網絡寬度。之前大量論文表明,ResNet使用的Residual結構比GoogLeNet使用的Inception結構在達到相同預測精度條件下的運行速度更快。AlphaGo Zero采用了Residual應該有速度方面的考慮。
杜克大學博士研究生謝知遙對此做了進一步闡述:
DeepMind的新算法AlphaGo Zero開始擺脫對人類知識的依賴:在學習開始階段無需先學習人類選手的走法,另外輸入中沒有了人工提取的特征 。
在網絡結構的設計上,新的算法與之前的AlphaGo有兩個大的區別。首先,與之前將走子策略(policy)網絡和勝率值(value)網絡分開訓練不同,新的網絡結構可以同時輸出該步的走子策略(policy)和當前情形下的勝率值(value)。實際上 policy與value網絡相當于共用了之前大部分的特征提取層,輸出階段的最后幾層結構仍然是相互獨立的。訓練的損失函數也同時包含了policy和value兩部分。這樣的顯然能夠節省訓練時間,更重要的是混合的policy與value網絡也許能適應更多種不同情況。
另外一個大的區別在于特征提取層采用了20或40個殘差模塊,每個模塊包含2個卷積層。與之前采用的12層左右的卷積層相比,殘差模塊的運用使網絡深度獲得了很大的提升。AlphaGo Zero不再需要人工提取的特征應該也是由于更深的網絡能更有效地直接從棋盤上提取特征。根據文章提供的數據,這兩點結構上的改進對棋力的提升貢獻大致相等。
因為這些改進,AlphaGo Zero的表現和訓練效率都有了很大的提升,僅通過4塊TPU和72小時的訓練就能夠勝過之前訓練用時幾個月的原版AlphaGo。在放棄學習人類棋手的走法以及人工提取特征之后,算法能夠取得更優秀的表現,這體現出深度神經網絡強大的特征提取能力以及尋找更優解的能力。更重要的是,通過擺脫對人類經驗和輔助的依賴,類似的深度強化學習算法或許能更容易地被廣泛應用到其他人類缺乏了解或是缺乏大量標注數據的領域。
AlphaGo優化意義何在?人工智能的將來又在哪里?
這個工作意義何在呢?人工智能專家、美國北卡羅萊納大學夏洛特分校洪韜教授也對知社發表了看法:
我非常仔細從頭到尾讀了這篇論文。首先要肯定工作本身的價值。從用棋譜(supervised learning)到扔棋譜,是重大貢獻(contribution)!干掉了當前最牛的棋手(變身前的阿法狗),是advancing state-of-the-art 。神經網絡的設計和訓練方法都有改進,是創新(novelty)。從應用角度,以后可能不再需要耗費人工去為AI的產品做大量的前期準備工作,這是其意義(significance)所在!
接著,洪教授也簡單回顧了人工神經網絡的歷史:
人工神經網絡在上世紀四十年代就出來了,小火了一下就撐不下去了,其中一個原因是大家發現這東西解決不了“異或問題”,而且訓練起來太麻煩。到了上世紀七十年代,Paul Werbos讀博時候拿backpropagation的算法來訓練神經網絡,提高了效率,用多層神經網絡把異或問題解決了,也把神經網絡帶入一個新紀元。上世紀八九十年代,人工神經網絡的研究迎來了一場大火,學術圈發了成千上萬篇關于神經網絡的論文,從設計到訓練到優化再到各行各業的應用。
Jim Burke教授,一個五年前退休的IEEE Life Fellow,曾經講過那個年代的故事:去開電力系統的學術會議,每討論一個工程問題,不管是啥,總會有一幫人說這可以用神經網絡解決,當然最后也就不了了之了。簡單的說是大家挖坑灌水吹泡泡,最后沒啥可忽悠的了,就找個別的地兒再繼續挖坑灌水吹泡泡。上世紀末的學術圈,如果出門不說自己搞神經網絡的都不好意思跟人打招呼,就和如今的深度學習、大數據分析一樣。
然后,洪教授對人工智能做了并不十分樂觀的展望:
回到阿法狗下棋這個事兒,伴隨著大數據的浪潮,數據挖掘、機器學習、神經網絡和人工智能突然間又火了起來。這次火的有沒有料呢?我認為是有的,有海量的數據、有計算能力的提升、有算法的改進。這就好比當年把backpropagation用在神經網絡上,的確是個突破。
最終這個火能燒多久,還得看神經網絡能解決多少實際問題。二十年前的大火之后,被神經網絡“解決”的實際問題寥寥無幾,其中一個比較知名的是電力負荷預測問題,就是用電量預測,剛好是我的專業。由于當年神經網絡過于火爆,導致科研重心幾乎完全離開了傳統的統計方法。等我剛進入這個領域做博士論文的時候,就拿傳統的多元回歸模型秒殺了市面上的各種神經網絡遺傳算法的。我一貫的看法,對于眼前流行的東西,不要盲目追逐,要先審時度勢,看看自己擅長啥、有啥積累,看準了坑再跳。
美國密歇根大學人工智能實驗室主任Satinder Singh也表達了和洪教授類似的觀點:這并非任何結束的開始,因為人工智能和人甚至動物相比,所知所能依然極端有限:
This is not the beginning of any end because AlphaGo Zero, like all other successful AI so far, is extremely limited in what it knows and in what it can do compared with humans and even other animals.
不過,Singh教授仍然對阿法元大加贊賞:這是一項重大成就, 顯示強化學習而不依賴人的經驗,可以做的更好:
The improvement in training time and computational complex?ity of AlphaGo Zero relative to AlphaGo, achieved in about a year, is a major achieve?ment… the results suggest that AIs based on reinforcement learning can perform much better than those that rely on human expertise.
陳怡然教授則對人工智能的未來做了進一步的思考:
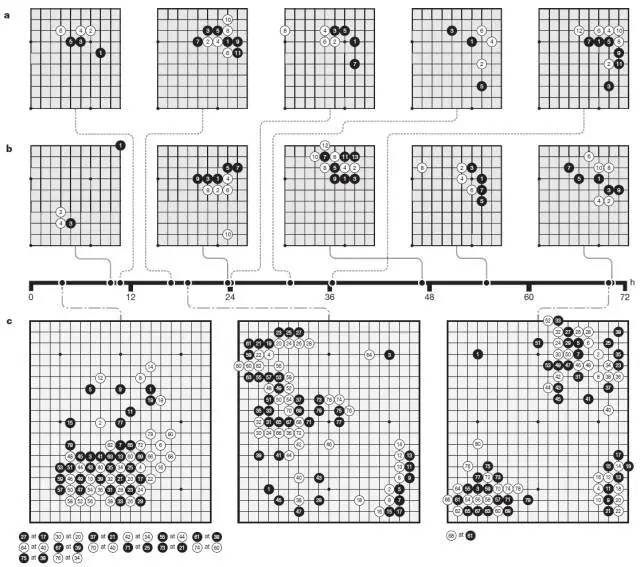
AlphaGo Zero沒有使用人類標注,只靠人類給定的圍棋規則,就可以推演出高明的走法。有趣的是,我們還在論文中看到了AlphaGo Zero掌握圍棋的過程。比如如何逐漸學會一些常見的定式與開局方法 ,如第一手點三三。相信這也能對圍棋愛好者理解AlphaGo的下棋風格有所啟發。
除了技術創新之外,AlphaGo Zero又一次引發了一個值得所有人工智能研究者思考的問題: 在未來發展中,我們究竟應該如何看待人類經驗的作用。在AlphaGo Zero自主學會的走法中,有一些與人類走法一致,區別主要在中間相持階段。AlphaGo Zero已經可以給人類當圍棋老師,指導人類思考之前沒見過的走法,而不用完全拘泥于圍棋大師的經驗。也就是說AlphaGo Zero再次打破了人類經驗的神秘感,讓人腦中形成的經驗也是可以被探測和學習的。
陳教授最后也提出一個有趣的命題:
未來我們要面對的一個挑戰可能就是: 在一些與日常生活有關的決策問題上,人類經驗和機器經驗同時存在,而機器經驗與人類經驗有很大差別,我們又該如何去選擇和利用呢?
不過David Silver對此并不擔心,而對未來充滿信心。他指出:
If similar techniques can be applied to other structured problems, such as protein folding, reducing energy consumption or searching for revolutionary new materials, the resulting breakthroughs have the potential to positively impact society.

不深思則不能造于道。不深思而得者,其得易失。
名人名言- 曾國藩
- By 知社學術圈
- 2017-10-19
- 10034
- 公司新聞,網站開發,網站設計,UI